
ChatGPT画像生成アップデート – GPT-4o Image Generation の解説
OpenAI が発表した GPT-4o は、テキスト、画像、音声、ビデオを統合的に扱える真のマルチモーダルモデルとして、AI の可能性を大きく広げています。特に、その画像生成機能は、従来の画像生成 AI を凌駕する性能と使いやすさを実現し、多くの注目を集めています。
この記事では、「4o Image Generation」をメインキーワードに、この技術の全貌を、 generative AI に関心のある読者に向けて詳細に解説します。
GPT-4o Image Generation の概要から、主要な特徴、技術的な詳細、以前のモデルとの違い、活用事例、メリット・デメリット、競合モデルとの比較、そして利用方法までを網羅的に解説することで、読者の皆様がこの最先端技術を深く理解し、自身の活動に取り入れるための一助となることを目指します。
GPT-4o Image Generationとは?
GPT-4o Image Generation は、2025年3月26日にOpenAI が発表した最新モデルである GPT-4o に搭載された画像生成機能です。
これにより、ユーザーは ChatGPT のインターフェース内で、テキストプロンプトを入力するだけで高品質な画像を直接生成することが可能になりました。この機能は、クリエイティビティの発揮、教育現場での活用、ビジネスにおける効率化など、多岐にわたる用途での利用が期待されています。
特筆すべき点として、GPT-4o は ChatGPT のデフォルトの画像生成モデルとして、以前の DALL-E 3 に取って代わったことが挙げられます。これは、OpenAI が GPT-4o の画像生成能力が DALL-E 3 を凌駕すると判断したことを示唆しており、ユーザーはより高度な画像生成機能をより手軽に利用できるようになったと言えるでしょう。
従来の画像生成モデルと比較して、GPT-4o はその進化において重要な違いを示しています。DALL-E 3 などの以前のモデルは、主に拡散モデルと呼ばれる技術を用いて画像を生成していましたが、GPT-4o はテキスト、画像、音声など、あらゆる種類のメディアを単一のモデルで同時に処理する能力を備えています。この統合的なアプローチにより、GPT-4o はテキストプロンプトからより文脈に沿った、より高品質な画像を生成することが可能になったと考えられます。
GPT-4o 画像生成は

このような画像もGPT-4o Image Generationで作成できます。
GPT-4o Image Generationは何ができるのか?
GPT-4o Image Generation は、以前のモデルと比較して、いくつかの重要な点で大幅な進化を遂げています。以下にその主要な特徴を詳しく見ていきましょう。
GPT-4oの画像生成機能は、従来モデルと比較して大幅な進化を遂げ、より高度で使いやすいものとなりました。主な進化点は以下の通りです。
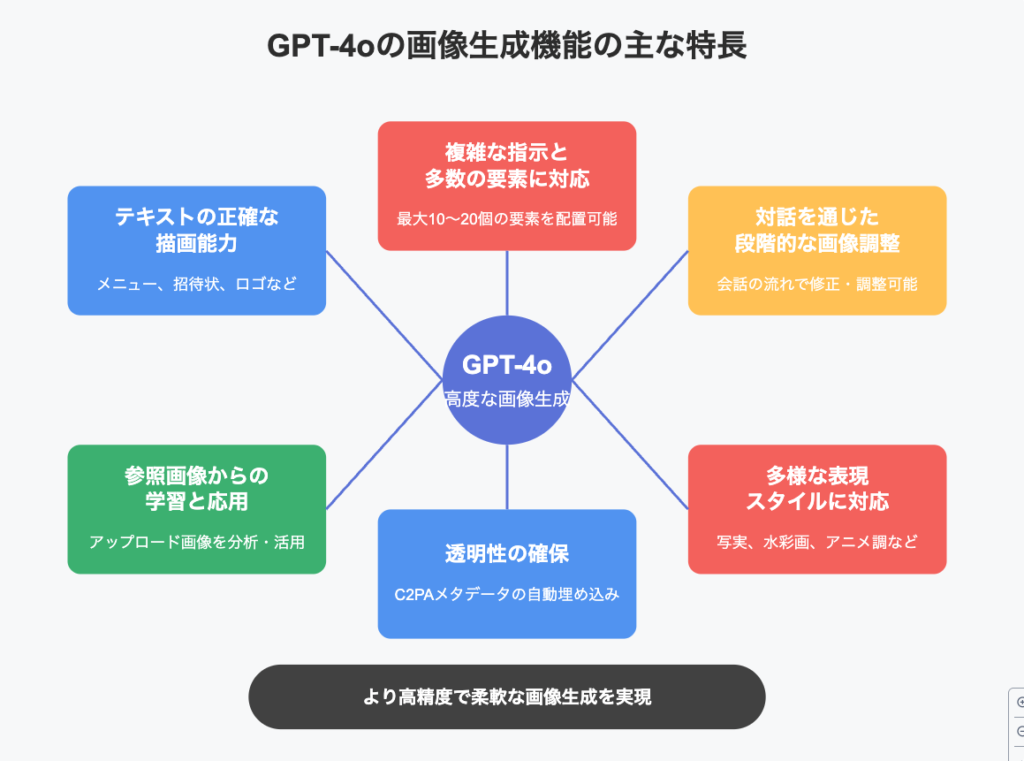
テキストの正確な描画能力の向上
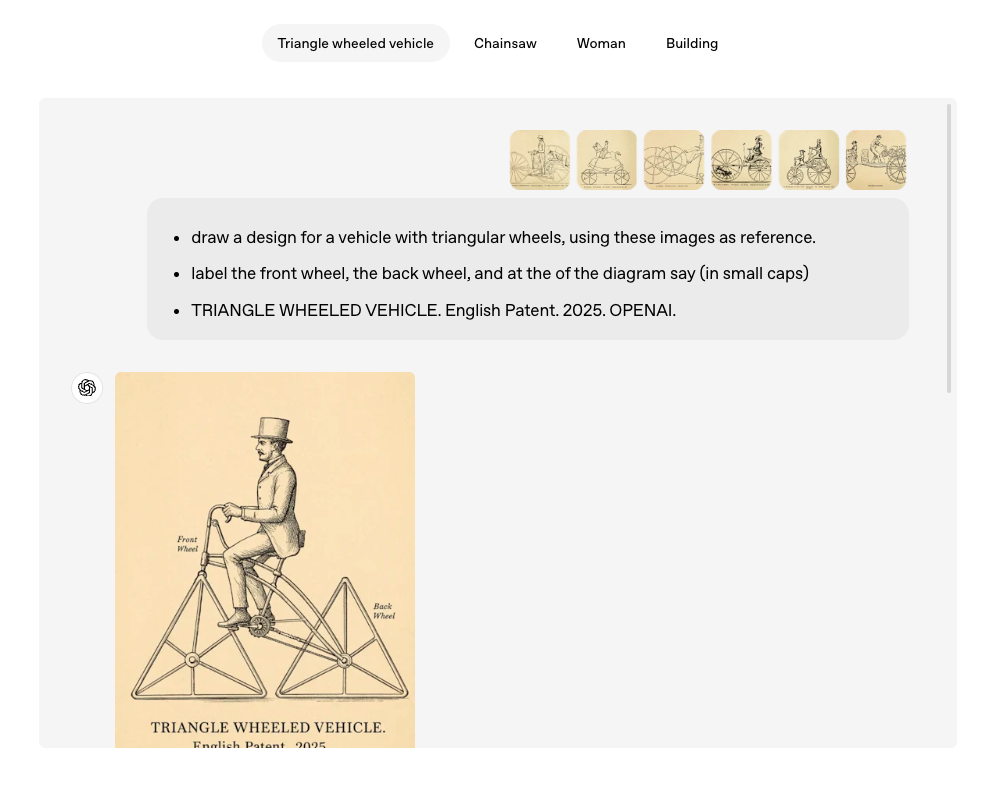
GPT-4oは、画像内にテキストを非常に高い精度で描画する能力が向上しました。これは、従来のAI画像生成モデルでは難しかった点です。
活用例: メニュー、招待状、プレゼンテーション資料、ロゴ、広告など、テキスト情報が重要な画像において、誤字脱字なく、デザインに調和したテキストを生成できます。これにより、追加のデザインツールなしで、テキストを含む画像をChatGPT内で完成させることが容易になります。
複雑な指示と多数の要素への対応強化
複数の要素(最大10〜20個程度)を含む、複雑な指示(プロンプト)を正確に理解し、画像内に適切に配置する能力が向上しました。従来モデルでは要素が増えると精度が低下する傾向がありましたが、この点が大きく改善されています。
活用例: 多くの人々や物で賑わう市場の風景、多数のデータ要素を含むインフォグラフィック、複数のキャラクターが特定のオブジェクトと関わる場面など、より詳細で複雑なシーンを指示通りに生成できます。
対話を通じた画像の段階的な調整が可能に
生成された画像に対して、自然な対話を通じて継続的に修正や調整を指示できる点が大きな特徴です。
活用例: 最初の生成結果に対し、「色合いを明るく変更してください」「背景を別のものに差し替えてください」「このオブジェクトを追加/削除してください」といった指示を会話の流れで与えることで、効率的に理想の画像に近づけることができます。例えば、キャラクターデザインの初期案を基に、服装や髪型、表情などを対話で微調整していくプロセスが可能です。
参照画像からの学習と応用
ユーザーがアップロードした画像を分析し、その内容やスタイルを学習して、新しい画像の生成に活用する機能が備わっています。
活用例: 手書きのスケッチを基に洗練されたポスターを作成したり、特定のカラースキームを持つ画像を参考に、その色調を反映した新しいイラストを生成したりできます。これにより、既存のビジュアル資産を元にした、よりパーソナライズされた画像生成が実現します。
透明性の確保 (C2PAメタデータ)
生成された画像には、それがAIによって生成されたことを示すためのC2PAメタデータが自動的に埋め込まれます。これにより、コンテンツの出所が明確になり、AI生成コンテンツの責任ある利用が促進されます。
多様な表現スタイルへの対応
写実的な表現から、水彩画、油絵、イラストレーション、アニメ調まで、非常に幅広いスタイルでの画像生成が可能です。特定のアーティストの作風を模倣することもできます。
活用例: 用途や好みに応じて、最適な表現スタイルの画像を生成することができます。
ホリエモンのyoutubeチェンネルでも紹介されています。
GPT-4oはどのように画像を生成するのか?
GPT-4o がどのようにしてこれほど高度な画像生成能力を実現しているのか、その技術的な詳細に迫ります。
自己回帰的な画像生成
GPT-4oは画像を一気に作り出すのではなく、「自己回帰的」と呼ばれる方法で順番に作ります。これは文章を1文字ずつ順番に生成するのと似ていて、画像の左上から右下へと、小さなブロック単位(トークンと呼ばれます)で少しずつ完成させていくやり方です。
これまでOpenAIが使っていたDALL-E 3という画像生成モデルは「拡散モデル」と呼ばれる技術を使っていました。これは、最初にノイズだらけの画像を用意し、そこから少しずつノイズを取り除いていくことで画像を作り出す方法です。
GPT-4oの自己回帰的な方法では、最初から順を追って画像を組み立てていくため、特に文字の描写や物体の配置などで、より正確に生成できると期待されています。
ハイブリッドモデルの可能性
一部の情報源では、GPT-4o は完全に自己回帰的なモデルではなく、自己回帰的なコンポーネントと拡散モデルのコンポーネントを組み合わせたハイブリッドモデルである可能性も示唆されています。
この場合、自己回帰的な部分が画像の全体的な構造や主要なコンテンツを生成し、拡散モデルの部分が細部のリアリズムや質感を高める役割を担っていると考えられます。
マルチスケール CLIP 様埋め込みと潜在空間での操作
GPT-4o は、おそらく LLAVA のような他の高度なマルチモーダルモデルと同様に、CLIP (Contrastive Language-Image Pre-training) に触発されたマルチスケール埋め込みを使用して、テキストプロンプトと視覚コンテンツの両方を共通の潜在空間にエンコードしていると考えられます。
潜在空間とは、複雑なデータ(例えば画像)を、より低次元のベクトル空間に圧縮して表現したものです。この空間内で、意味的に類似したデータは互いに近い位置に配置されます。
GPT-4o は、テキストプロンプトをこの潜在空間内の特定の点にマッピングし、そこから画像をデコードすることで、プロンプトに対応した画像を生成していると考えられます。画像をトークンと呼ばれる小さな単位のシーケンスとして扱うことも、このプロセスの重要な要素です。
Transformer アーキテクチャ
GPT-4o は、GPT シリーズの一員であるため、その基盤には Transformer アーキテクチャが用いられています。Transformer は、自然言語処理の分野で大きな成功を収めてきたニューラルネットワークアーキテクチャであり、近年では画像生成を含む様々なタスクに応用されています。
Transformer の重要な要素の一つに、注意機構(Attention Mechanism)があります。これは、モデルが入力されたテキストや画像の中で、最も重要な部分に焦点を当てることを可能にする仕組みです。
GPT-4o は、この注意機構を効果的に活用することで、プロンプトの意図を正確に理解し、それに対応した画像を生成していると考えられます。
また、エンコーダー・デコーダー構造が用いられている可能性もあり、エンコーダーが入力プロンプトを処理し、デコーダーがそれに基づいて画像を生成するという役割分担が行われているかもしれません。
GPT-4oは何が違うのか?
GPT-4o Image Generation は、以前の OpenAI の画像生成モデルである DALL-E 3 と比較して、いくつかの重要な点で違いが見られます。
統合モデル vs. 独立したシステム
最も大きな違いの一つは、GPT-4o の画像生成機能が、テキスト処理や他のモダリティ処理を行うのと同じ基盤モデルに統合されている点です。
一方、DALL-E 3 は、主に画像生成に特化した独立したシステムでした。この統合により、GPT-4o は ChatGPT がテキストから学習した豊富な知識を画像生成に活用できるため、より文脈に沿った画像を生成できると考えられます。
生成方法
GPT-4o は自己回帰的なアプローチを採用しているのに対し、DALL-E 3 は主に拡散モデルを使用していました。この根本的な技術の違いが、テキストレンダリングの精度や、多数のオブジェクトを含むプロンプトの処理能力の向上に貢献していると考えられます。
テキストレンダリング能力
GPT-4o は、画像内のテキストを正確にレンダリングする能力において、DALL-E 3 から大幅な改善を見せています。これは、ビジネス用途や情報伝達の観点から非常に重要な進歩です。
多数のオブジェクトの処理
GPT-4o は、プロンプトに含まれるオブジェクトの数をより多く(10〜20 個程度)処理できるのに対し、DALL-E 3 はそれよりも少ない数(5〜8 個程度)のオブジェクトを扱うのが得意でした。
生成速度
自己回帰的な生成方法を採用しているため、GPT-4o の画像生成速度は DALL-E 3 と比較してわずかに遅い可能性があります。ただし、生成される画像の品質と精度を考慮すると、このトレードオフは許容範囲内であると考えられます。
編集機能
GPT-4o は、ChatGPT のチャットインターフェース内で、自然な会話を通じて画像を編集する機能がより直感的になっています。DALL-E 3 にも編集機能は存在しましたが、GPT-4o の方がよりシームレスな体験を提供していると言えるでしょう。
アクセス
GPT-4o の画像生成機能は、無料プランを含むすべての ChatGPT サブスクリプションティアで利用可能であり、DALL-E 3 よりも幅広いユーザーが利用できるようになっています。
これらの比較から、GPT-4o は OpenAI の画像生成技術において、DALL-E 3 から大きく進化しており、より統合的で、より高性能で、より使いやすい画像生成体験を提供していると言えるでしょう。
GPT-4o Image Generationはどのように役立つのか?
GPT-4o Image Generation は、その高度な機能により、様々な分野での活用が期待されています。
マーケティング資料
広告、ソーシャルメディアコンテンツ、ウェブサイトのバナーなど、テキストとビジュアルが調和したマーケティング資料を効率的に作成できます。
ロゴとブランドアセットのデザイン
独自のロゴやブランドイメージに合致したイラストレーション、アイコンなどを、正確なタイポグラフィと共に生成できます。
教育資料とインフォグラフィック
複雑な概念を図解したイラストや、データを分かりやすく提示するインフォグラフィックなどを容易に作成できます。
ユーザーインターフェースデザイン
ウェブサイトやアプリケーションのモックアップ、アイコン、UI エレメントなどを迅速に生成し、デザインプロセスを効率化できます。
製品モックアップ
新しい製品のアイデアをリアルに可視化するためのモックアップを生成し、プレゼンテーションや市場調査に活用できます。
プレゼンテーション資料
説得力のあるビジュアルを生成し、プレゼンテーションの効果を高めることができます。
コミックブックとストーリーテリング
一貫性のあるキャラクターと正確なテキストを含む、視覚的な物語や連続したアートワークを作成できます。
写真編集と画像補正
既存の画像を修正したり、不要な要素を削除したり、背景を変更したり、色調を調整したりといった編集作業を、会話形式の指示で行うことができます。
ミーム生成
トレンドに合わせた面白いミームを素早く作成し、ソーシャルメディアでのエンゲージメントを高めることができます。
ゲームアセットの作成
インディーゲーム開発において、キャラクターのスプライト、背景テクスチャ、環境要素などを生成し、開発プロセスを加速できます。
これらの活用事例は、GPT-4o Image Generation が、創造的な活動からビジネス、教育まで、幅広い分野でその可能性を発揮することを示唆しています。
メリットとデメリット
GPT-4o Image Generation は多くのメリットを提供する一方で、いくつかのデメリットも存在します。
メリット
- 正確なテキストレンダリング
- 複雑なプロンプトと多数のオブジェクトの処理能力の向上
- 直感的で使いやすいマルチターン生成と会話による洗練
- ユーザーアップロード画像からのインコンテキスト学習
- 世界知識の統合による、より文脈に沿った出力
- 多様なスタイルでの画像生成
- 透明性を高める C2PA メタデータの自動埋め込み
- 無料プランを含むすべての ChatGPT サブスクリプションティアで利用可能
- コンテンツ作成とデザインワークフローの効率化の可能性
デメリット
- 拡散モデルと比較して生成速度が遅い可能性
- ポスターのような縦長の画像で、下部がトリミングされる可能性
- 曖昧なプロンプトに対して、事実に基づかない内容(ハルシネーション)を生成する可能性
- 非常に多くのオブジェクト(20個以上)を含むシーンの正確な描写の難しさ
- 非ラテン文字のレンダリングにおける潜在的な問題
- 特定の画像部分の編集や、アップロードされた画像の顔の一貫性を保つことの難しさ(バグ修正予定)
- 小さなテキストの視認性の低下
- 著作権侵害や有害コンテンツ生成への悪用の可能性(安全対策は実施済み)
これらのメリットとデメリットを理解することで、ユーザーは GPT-4o Image Generation をより効果的に活用し、その潜在的な課題を認識することができます。
競合モデルとの比較:GPT-4o vs. Midjourney, Stable Diffusionなど
AI 画像生成の分野では、GPT-4o 以外にも多くの強力なモデルが存在します。ここでは、主要な競合モデルである Midjourney と Stable Diffusion との比較を行います。
GPT-4o vs. Midjourney
| 機能 | GPT-4o | Midjourney |
| 主な機能 | マルチモーダル AI と統合された画像生成 | 専用の画像生成ツール |
| 生成方法 | 自己回帰(またはハイブリッド) | 拡散 |
| テキストレンダリング | 優れている | 弱い |
| プロンプト処理 | 最大 10-20 個のオブジェクト、会話による洗練 | 複雑なプロンプトは難しい場合がある |
| 生成速度 | 中程度(遅い可能性あり) | 中程度 |
| 使いやすさ | 高い(ChatGPT に統合) | 中〜高(Discord が必要、プロンプト構文あり) |
| 画像編集 | 会話形式、統合されている | 主にプロンプトベース |
| 典型的な出力スタイル | バランスが取れている、実用性重視 | 高度に芸術的、様式化されている |
| オープンソース | いいえ | いいえ |
| 主なインターフェース | ChatGPT チャットインターフェース | Discord |
| 制御/カスタマイズ | 中程度(自然言語プロンプトによる) | 中程度(プロンプトパラメータとコマンドによる) |
GPT-4o は、テキストレンダリング能力と ChatGPT への統合による使いやすさが際立っています。
一方、Midjourney は、特に芸術的で美しい画像を生成することに強みを持っており、デジタルアーティストやクリエイターに人気があります。
GPT-4o は、より実用的な用途に適しており、テキストと画像を組み合わせたコンテンツの作成において、Midjourney よりも優位性があると言えるでしょう。
GPT-4o vs. Stable Diffusion
| 機能 | GPT-4o | Stable Diffusion |
| 主な機能 | マルチモーダル AI と統合された画像生成 | オープンソースの画像生成モデル |
| 生成方法 | 自己回帰(またはハイブリッド) | 潜在拡散 |
| テキストレンダリング | 優れている | 中程度(モデルやテクニックによる) |
| プロンプト処理 | 最大 10-20 個のオブジェクト、会話による洗練 | パラメータを通じて高度にカスタマイズ可能 |
| 生成速度 | 中程度(遅い可能性あり) | 速い |
| 使いやすさ | 高い(ChatGPT に統合) | 中〜高(様々な UI ツールあり) |
| 画像編集 | 会話形式、統合されている | 非常に広範(インペインティング、アウトペインティングなど) |
| 典型的な出力スタイル | バランスが取れている、実用性重視 | 非常に多様、モデルと設定に依存 |
| オープンソース | いいえ | はい |
| 主なインターフェース | ChatGPT チャットインターフェース | 様々なスタンドアロンアプリ、ウェブ UI、API |
| 制御/カスタマイズ | 中程度(自然言語プロンプトによる) | 高い(多数のパラメータ、モデル、LoRA による) |
Stable Diffusion はオープンソースであるため、高度なカスタマイズが可能であり、生成速度も速いという利点があります。
一方、GPT-4o はテキストレンダリング能力に優れており、ChatGPT への統合により、より手軽に利用できます。Stable Diffusion は、より技術的な知識を持つユーザーや、特定のニーズに合わせてモデルを調整したいユーザーに適していると言えるでしょう。
GPT-4o Image Generationを始めるには:利用方法、料金、API
GPT-4o Image Generation を始めるための手順、料金、そして API の利用について解説します。
ChatGPT を通じたアクセス
GPT-4o の画像生成機能は、ChatGPT のインターフェース内で直接利用することができます。特別な設定や追加のツールは必要ありません。
対応サブスクリプションティア
この機能は、無料プランを含むすべての ChatGPT サブスクリプションティアのユーザーが利用できます。ただし、無料プランのユーザーには、利用回数に制限がある場合があります。
画像生成の手順
- ChatGPT にアクセス
- ChatGPT のウェブサイトまたはモバイルアプリを開きます。GPT-4o モデルが選択されていることを確認してください(通常はデフォルトで選択されています)。
- プロンプトの作成
- チャットウィンドウに、生成したい画像を自然な言葉で具体的に記述したプロンプトを入力します。主題、スタイル、色、構図などをできるだけ詳細に記述することが、より良い結果を得るための鍵となります。
- 画像の生成
- プロンプトを送信します。GPT-4o はリクエストを処理し、通常約 1 分以内に画像をチャットウィンドウに表示します。
- 会話による洗練
- 生成された画像が意図したものでない場合は、続けてプロンプトを入力することで、色、スタイル、要素の追加や削除など、様々な修正を指示できます。GPT-4o は、会話の流れを理解し、修正された画像を生成します。
- 画像の保存
- 生成された画像に満足したら、ダウンロードアイコンまたはメニューオプションを選択して、画像をデバイスに保存します。通常、PNG 形式で保存されます。
効果的なプロンプトの書き方のヒント
- 具体的かつ詳細に記述する。
- 描写的な形容詞や副詞を使用する。
- 希望するアートスタイルを指定する(例:写真のようにリアル、イラスト、水彩画)。
- 含んでほしくない要素は否定的なプロンプトで指定する。
- アスペクト比を指定する(例:横長、縦長、正方形)。
- 参考となる画像をアップロードして、スタイルや要素の取り込みを指示する。
料金と利用制限
無料ユーザーにも公開されており、誰でも使うことが可能になっています。
ただし、無料プランのユーザーは、画像生成の回数に制限がある可能性があります。
画像を多く生成する方については有料プラン(Plus、Pro、Team)を活用するといいでしょう。
API アクセス
OpenAI は、近いうちに GPT-4o Image Generation の API を開発者向けに公開する予定です。これにより、開発者は自身のアプリケーションやサービスに GPT-4o の画像生成機能を統合できるようになります。それまでの間、プログラムから画像生成を行いたい開発者は、既存の DALL-E 3 API を利用することができます。
知っておくべき技術用語解説
- Generative AI (生成AI)
- トレーニングデータに似た新しい、現実的なデータ(テキスト、画像、音声、ビデオなど)を作成することに焦点を当てた AI の分野。
- Large Language Model (LLM)
- 大量のテキストデータでトレーニングされた高度な AI モデルで、人間のような言語を理解、解釈、生成する能力を持つ。GPT-4o は、テキストだけでなく画像などの他のメディアも処理できるマルチモーダル LLM の一例。
- Multimodal AI (マルチモーダル AI)
- テキスト、画像、音声、ビデオなど、複数の種類のデータ入力(モダリティ)を処理および理解できる AI システム。多くの場合、これらの異なる形式で出力を生成することも可能。GPT-4o はマルチモーダル AI の代表的な例。
- Autoregressive Model (自己回帰モデル)
- シーケンス内の以前の要素に基づいて、次の要素を予測するタイプの機械学習モデル。GPT-4o は、画像生成プロセスにおいて自己回帰的なアプローチ(またはハイブリッド)を採用し、画像を逐次的に構築する。
- Diffusion Model (拡散モデル)
- トレーニングデータに徐々にノイズを追加するプロセスを学習し、それを逆転させることでデータを生成する生成モデルの一種。DALL-E 3 や Stable Diffusion などのモデルは、画像生成に拡散ベースの手法を使用する。
- Latent Space (潜在空間)
- AI モデルによって学習された、複雑なデータ(画像など)の低次元で抽象的な表現。この圧縮された空間内で操作することで、モデルは効率的に新しいデータを処理、理解、生成できる。
- Tokenization (トークン化)
- 入力データ(テキストまたは画像)を、AI モデルが処理できるより小さな離散単位(トークン)に分割するプロセス。画像の場合、これらのトークンは小さなパッチや視覚的特徴を表すことがある。
- Embeddings (埋め込み)
- トークン(単語または画像の特徴)の意味的関係を捉えた、高密度なベクトル表現。これらの数値表現により、AI モデルはデータの理解と生成のための数学的操作を実行できる。
- Transformer Architecture (Transformer アーキテクチャ)
- GPT-4o を含む多くの最先端 AI モデルの基盤となっている強力なニューラルネットワークアーキテクチャ。その主要な革新は、モデルが入力データの異なる部分の重要度を重み付けすることを可能にする自己注意機構。
- Attention Mechanism (注意機構、特に自己注意)
- Transformer アーキテクチャの中核となるコンポーネントで、モデルが入力シーケンス(テキストまたは視覚トークン)の最も関連性の高い部分に焦点を当てて出力を生成することを可能にする。入力内の異なる要素間の関係と依存性を理解するのに役立つ。
- C2PA Metadata (C2PA メタデータ、Content Authenticity Initiative)
- 画像を含むデジタルコンテンツの起源と編集履歴に関する情報を提供するための業界標準。GPT-4o は、透明性を提供し、AI によって生成されたコンテンツを識別するのに役立つように、生成された画像にこのメタデータを自動的に含める。
GPT-4o Image Generationの可能性と未来
GPT-4o Image Generation は、言語理解と視覚創造の強力な融合を、アクセスしやすい単一のプラットフォーム内で実現する、AI の進化における重要な一歩を示しています。テキストレンダリングの精度向上、複雑なプロンプトの処理能力の向上、会話による洗練を可能にする直感的なユーザーエクスペリエンスなど、その主要な進歩は明らかです。
この技術は、マーケティング、コンテンツ制作、教育、デザイン、エンターテインメントなど、様々な業界にわたって変革の可能性を秘めており、高品質でカスタマイズされたビジュアルコンテンツの生成をより身近で容易なものにしています。
GPT-4o は大きな進歩を遂げましたが、生成速度や特定条件下での一貫性など、まだ改善の余地があることも事実です。しかし、継続的な研究開発により、これらの課題は克服され、モデルの能力はさらに向上していくでしょう。
より広範な視点で見ると、GPT-4o Image Generation は、強力な AI 機能をユーザーフレンドリーなインターフェースに直接統合するという、より大きなトレンドを象徴しています。この傾向は、高度なテクノロジーへのアクセスを民主化し、より多くの人々が創造性とイノベーションの可能性を解き放つことを可能にします。AI 画像生成の未来は非常に有望であり、GPT-4o はその進化において中心的な役割を果たすことが期待されます。
引用文献
- GPT-4o Image Generation: A Guide With 8 Examples | DataCamp, 3月 28, 2025にアクセス、 https://www.datacamp.com/tutorial/gpt-4o-image-generation
- Generate AI Images with ChatGPT: OpenAI’s GPT-4o Now Replaces DALL-E 3 – Karmactive, 3月 28, 2025にアクセス、 https://www.karmactive.com/generate-ai-images-with-chatgpt-openais-gpt-4o-now-replaces-dall-e-3/
- OpenAI Introduces GPT-4o Image Generation, Replaces DALL-E 3 – Outlook Business, 3月 28, 2025にアクセス、 https://www.outlookbusiness.com/start-up/news/openai-introduces-gpt-4o-image-generation-replaces-dall-e-3
- GPT-4o Image Generation: OpenAI Just Perfected AI Image Generation | by Amdadul Haque Milon | Towards AGI | Mar, 2025 | Medium, 3月 28, 2025にアクセス、 https://medium.com/towards-agi/gpt-4o-image-generation-openai-just-perfected-ai-image-generation-137679a039c6
- OpenAI Rolls Out GPT-4o Image Creation To Everyone, 3月 28, 2025にアクセス、 https://www.searchenginejournal.com/openai-rolls-out-gpt-4o-image-creation-to-everyone/542910/
- Introducing 4o Image Generation – OpenAI, 3月 28, 2025にアクセス、 https://openai.com/index/introducing-4o-image-generation/
- ChatGPT Can Finally Generate Images With Legible Text, 3月 28, 2025にアクセス、 https://www.howtogeek.com/chatgpt-4o-image-generation/
- GPT-4o Image Generation Review: The Best AI Image Generator Yet? – Magic Hour, 3月 28, 2025にアクセス、 https://magichour.ai/blog/gpt-4o-image-generation-review
- 「GPT‑4o 画像生成・編集」が登場!以前のDalleから圧倒的進化で …, 3月 28, 2025にアクセス、 https://note.com/masa_wunder/n/necb5e878570b
- 4o Image Generation の概要|npaka – note, 3月 28, 2025にアクセス、 https://note.com/npaka/n/nccb2426260f9
- 4o doesn’t use diffusion and it’s better at many things!! : r/StableDiffusion – Reddit, 3月 28, 2025にアクセス、 https://www.reddit.com/r/StableDiffusion/comments/1jkyh7o/4o_doesnt_use_diffusion_and_its_better_at_many/
- Diffusion Models: A Practical Guide – Scale AI, 3月 28, 2025にアクセス、 https://scale.com/guides/diffusion-models-guide
- Understanding Image Generation with Diffusion | by Deven Joshi – Medium, 3月 28, 2025にアクセス、 https://medium.com/@dev.n/understanding-image-generation-with-diffusion-78eea7e7d6f8
- A Guide To Diffusion Based Image Generation | by Shashank Bhushan – Medium, 3月 28, 2025にアクセス、 https://medium.com/@bhushan.shashank93/a-guide-to-diffusion-based-image-generation-ee3ded234fbd
- What are Diffusion Models? – IBM, 3月 28, 2025にアクセス、 https://www.ibm.com/think/topics/diffusion-models
- Introduction to Diffusion Models for Machine Learning – AssemblyAI, 3月 28, 2025にアクセス、 https://www.assemblyai.com/blog/diffusion-models-for-machine-learning-introduction
- [D] GPT-4o image generation and editing – how??? : r/MachineLearning – Reddit, 3月 28, 2025にアクセス、 https://www.reddit.com/r/MachineLearning/comments/1jkt42w/d_gpt4o_image_generation_and_editing_how/
- A Comprehensive Guide to Latent Space | by AI Maverick, 3月 28, 2025にアクセス、 https://samanemami.medium.com/a-comprehensive-guide-to-latent-space-9ae7f72bdb2f
- Generative models and their latent space – The Academic, 3月 28, 2025にアクセス、 https://theacademic.com/generative-models-and-their-latent-space/
- What Is the Latent Space of an Image Synthesis System? – Blog – Metaphysic.ai, 3月 28, 2025にアクセス、 https://blog.metaphysic.ai/what-is-the-latent-space-of-an-image-synthesis-system/
- What is a Latent Space? – Medium, 3月 28, 2025にアクセス、 https://medium.com/@180031223cse/latent-space-the-invisible-playground-of-generative-ai-5b02e51946b8
- Text-to-image: latent diffusion models – National Innovation Centre for Data, 3月 28, 2025にアクセス、 https://nicd.org.uk/knowledge-hub/image-to-text-latent-diffusion-models
- GPT-4oとGemini-2.0の画像生成能力はいかにして作られているのか, 3月 28, 2025にアクセス、 https://zenn.dev/discus0434/articles/gemini-2-0-mm
- Transformer (deep learning architecture) – Wikipedia, 3月 28, 2025にアクセス、 https://en.wikipedia.org/wiki/Transformer_(deep_learning_architecture)
- How Transformers Work: A Detailed Exploration of Transformer Architecture – DataCamp, 3月 28, 2025にアクセス、 https://www.datacamp.com/tutorial/how-transformers-work
- Using transformer neural network architecture with images – Data Hub Tech Talk – YouTube, 3月 28, 2025にアクセス、 https://www.youtube.com/watch?v=0gIIzUufW5A
- arxiv.org, 3月 28, 2025にアクセス、 http://arxiv.org/pdf/1802.05751
- LLM Transformer Model Visually Explained – Polo Club of Data Science, 3月 28, 2025にアクセス、 https://poloclub.github.io/transformer-explainer/
- Image Synthesis using Pixel CNN based Autoregressive Generative Model | by Kartik Chaudhary | Game of Bits | Medium, 3月 28, 2025にアクセス、 https://medium.com/game-of-bits/image-synthesis-using-pixel-cnn-based-autoregressive-generative-model-05179bf662ff
- How to Use DALL-E 3: Tips, Examples, and Features | DataCamp, 3月 28, 2025にアクセス、 https://www.datacamp.com/tutorial/an-introduction-to-dalle3
- GPT-4o Image Generation vs MidJourney: ChatGPT AI Showdown – Sam & Elon Art Tests!, 3月 28, 2025にアクセス、 https://www.youtube.com/watch?v=YNSMJab6Bos
- I tried ChatGPT’s new image generator, and it shattered my expectations – ZDNET, 3月 28, 2025にアクセス、 https://www.zdnet.com/article/i-tried-chatgpts-new-image-generator-and-it-shattered-my-expectations/
- Comparing Image Generation Capabilities of ChatGPT 4, Gemini, and Midjourney in Practical Applications | by Mengya (Mia) Hu | Medium, 3月 28, 2025にアクセス、 https://medium.com/@humengyamia/comparing-image-generation-capabilities-of-chatgpt-4-gemini-and-midjourney-in-practical-a72d7f791e2a
- ChatGPT4o(GPT-4o)の画像生成とは?使い方や料金、プロンプトを解説! | AI総合研究所, 3月 28, 2025にアクセス、 https://www.ai-souken.com/article/what-is-gpt4o-image-generation
- GPT-4oでの画像生成のやり方を徹底解説:プロンプト、API活用法 …, 3月 28, 2025にアクセス、 https://hellocraftai.com/blog/386/
- Image generation – OpenAI API, 3月 28, 2025にアクセス、 https://platform.openai.com/docs/guides/image-generation
- How can I generate variations of the images produced by DALL-e 3? – API, 3月 28, 2025にアクセス、 https://community.openai.com/t/how-can-i-generate-variations-of-the-images-produced-by-dall-e-3/601939
- How to Use DALL-E 3 API for Image Generation? – Analytics Vidhya, 3月 28, 2025にアクセス、 https://www.analyticsvidhya.com/blog/2024/07/dall-e3/
- DALLE-3 API Takes Images as Inputs or Not? – OpenAI Developer Community, 3月 28, 2025にアクセス、 https://community.openai.com/t/dalle-3-api-takes-images-as-inputs-or-not/609779
- 大規模言語モデル(LLM)とは?定義、重要性、ユースケース、評価や価格競争について解説, 3月 28, 2025にアクセス、 https://www.gartner.co.jp/ja/articles/large-language-models
- 大規模言語モデルの仕組みとは?基本から学習方法まで徹底解説! – Alibaba Cloud, 3月 28, 2025にアクセス、 https://www.alibabacloud.com/help/ja/cloud-migration-guide-for-beginners/latest/llm-mechanism
- 大規模言語モデル(LLM)がもたらすAIチャットボットの進化 – AIさくらさん, 3月 28, 2025にアクセス、 https://www.tifana.ai/article/aifaqsystem-article-560
- 大規模言語モデル(LLM)とは?仕組み・種類・活用サービス・課題をわかりやすく解説 – AIsmiley, 3月 28, 2025にアクセス、 https://aismiley.co.jp/ai_news/what-is-large-language-models/
- 大規模言語モデル(LLM)とは?仕組み・種類・活用事例5選を徹底解説 – HBLAB, 3月 28, 2025にアクセス、 https://hblab.co.jp/blog/what-is-large-language-model/
- LLM(大規模言語モデル)を分かりやすく解説!簡単な仕組み・種類・活用事例を紹介!, 3月 28, 2025にアクセス、 https://www.ask-corp.jp/biz/column/large-language-models.html
- 大規模言語モデル | 用語解説 | 野村総合研究所(NRI), 3月 28, 2025にアクセス、 https://www.nri.com/jp/knowledge/glossary/llm.html
- 生成AI業界の真の勝者:2024年最新動向と主要プレーヤー10社の徹底解析 – note, 3月 28, 2025にアクセス、 https://note.com/brightiers/n/n7aa7bf175e20
- What are Autoregressive Models? – AR Models Explained – AWS, 3月 28, 2025にアクセス、 https://aws.amazon.com/what-is/autoregressive-models/
- Generating High-Resolution Images Using Deep Autoregressive Models – Medium, 3月 28, 2025にアクセス、 https://medium.com/towards-data-science/generating-high-resolution-images-using-autoregressive-models-3683f9af0db4
- Tutorial 12: Autoregressive Image Modeling — UvA DL Notebooks v1.2 documentation, 3月 28, 2025にアクセス、 https://uvadlc-notebooks.readthedocs.io/en/latest/tutorial_notebooks/tutorial12/Autoregressive_Image_Modeling.html
- NeurIPS Poster Autoregressive Image Generation without Vector Quantization, 3月 28, 2025にアクセス、 https://neurips.cc/virtual/2024/poster/94905
- 人工知能におけるトランスフォーマーとは何ですか? – AWS, 3月 28, 2025にアクセス、 https://aws.amazon.com/jp/what-is/transformers-in-artificial-intelligence/
- Transformerとは?何がすごい?仕組み、特徴、ChatGPTのベースにもなったディープラーニングモデルを詳しく解説 – AI Market, 3月 28, 2025にアクセス、 https://ai-market.jp/technology/transformer-chatgpt/
- Transformerアーキテクチャの完全ガイド:Encoder-only、Decoder-only – デイリーライフAI, 3月 28, 2025にアクセス、 https://daily-life-ai.com/251/
最後に
その他のAIツールについても、こちらから解説しています。ぜひお役立てくださいね。
加速度的に革新が起こるAI業界についていくためには、常にアンテナを張って情報をキャッチし続ける必要があります。ですが、普段お仕事で忙しい毎日を過ごしている皆様にとって、それは簡単なことではないでしょう。
そこで、我々BuzzConnection/KAGEMUSHAが皆様の生成AI活用についてのお手伝いを致します。業務フローへのAI導入に関わるコンサルティングや研修セミナーの実施から、対話型デジタルヒューマン制作/AI動画生成、AIチャットボット開発まで包括的なサポートを行っております。
株式会社BuzzConnectionについて
BuzzConnectionが提供する生成AIビジネス活用に向けたサービス
1. 生成AIに関する研修セミナーの実施
基本的な内容から発展的なビジネス活用まで様々なニーズに合わせた研修プログラムを用意しております。
2. 業務フローへのAI導入コンサルティング
解決したいソリューションに最適な生成AIサービスや導入の方法について、丁寧にご提案いたします。
新たな業務フローの運用についても、二人三脚でお手伝いいたします。
3. SNSマーケティングを革命するWebアプリ「バズコネ」
AIを用いた投稿の自動生成×投稿インサイトの分析×競合ベンチマークの分析
SNSマーケティングの業務効率化をたった1つのアプリで実現できます。
株式会社KAGEMUSHAについて
KAGEMUSHAが提供する生成AIビジネス活用に向けたサービス
1. 対話型デジタルヒューマン・AIキャラクター制作/動画制作事業
【対話型デジタルヒューマン/AIキャラクター制作】
まるで人間と話しているかのような自然な対話を可能にするAIキャラクターです。接客やカスタマーサポート、教育、イベント案内など、さまざまなシーンで活用可能です。
【デジタルヒューマン/AIキャラクター制作】
単なる「デジタルな存在」を超え、まるで実在の人物のような、貴社だけのオリジナルデジタルヒューマンAIキャラクターを制作
【動画制作】
企画から納品までワンストップで、ハイクオリティな動画を制作。AIを活用し効果的なプロモーションを実現します。。
2. AIチャットボット開発
チャットボットは、AIを活用した対話型システムで、テキストや音声を通じてユーザーとのコミュニケーションを自動化します。主に企業のカスタマーサポートや業務効率化、ユーザーエンゲージメント向上を目的に利用されています。
3. eラーニング/生成AI研修
AIの基礎知識から最新技術まで、分かりやすく解説。
AIを活用した業務効率化や新たなビジネスモデルの構築を支援します。
さらに、デジタルヒューマン研修も実施。
ご興味が御有りでしたら、是非とも下のフォームよりお問い合わせください。

お問い合わせフォーム
バズコネのおすすめ投稿
はコーディングに活用できる?プログラミングでの活用事例やメリットを紹介")

はコーディングに活用できる?プログラミングでの活用事例やメリットを紹介")





















コメント
コメント一覧 (1件)
[…] ChatGPT画像生成アップデート – GPT-4o Image Generation の解説 GPT-4o […]