
Gemini 2.5 Flashの画像生成が凄い!使い方・性能と「Deep Research」活用事例を解説
近年、AI技術は目覚ましい進化を続けており、私たちの仕事や創造性を大きく変えようとしています。特に注目を集めているのが、Googleが開発した最新の大規模言語モデル(LLM)「Gemini」シリーズです。その中でも、高速性と効率性を追求した「Gemini 2.5 Flash」モデルと、AIによる「画像生成」技術の組み合わせは、多くの可能性を秘めています。
「Gemini 2.5 Flashで画像生成はできるの?」
「話題のDeep Researchって何?画像生成とどう関係するの?」
「実際にどんな画像が作れるのか知りたい!」
この記事では、こうした疑問に答えるべく、Google AIの最前線であるGemini 2.5 Flashの概要から、注目される画像生成機能、そして「Deep Research」との連携や具体的な活用事例まで、最新情報(2025年4月時点)を基に徹底解説します。AIによるクリエイティブ表現の未来を、一緒に見ていきましょう。
【1分で完了】AI活用度診断

あなたのAI活用度を5つの観点で診断し、レーダーチャートで可視化。得意分野と伸ばすべきAIスキルが一目でわかります。
診断は無料で1分程度で完了するので、自分のAIスキルを伸ばしたい方はぜひ診断してみてください。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!

高速・軽量モデル「Gemini Flash」とは?
Googleが発表した「Gemini 2.5」は、マルチモーダル(テキスト、画像、音声、動画などを扱える)性能を特徴とする、非常に強力なAIモデルファミリーです。このファミリーは、性能や用途に応じて最適化された複数のモデルで構成されています。
Gemini Ultra
最高性能を誇るフラッグシップモデル。
Gemini Pro
高性能と汎用性のバランスが取れたモデル。
Gemini Flash
高速性と効率性を最優先に設計された軽量モデル。
オンデバイスでの利用に最適化された小型モデル。
今回注目する「Gemini Flash」は、この中で最も高速な応答速度と低い運用コストを実現することを目指したモデルです。
Flashモデルの主な特徴とメリット
圧倒的な応答速度
ユーザーの入力に対して素早く反応するため、リアルタイム性の高いアプリケーションに適しています。
高いコスト効率
少ない計算リソースで動作するため、API利用料などのコストを抑えることができます。大量のリクエストを処理するサービスにも向いています。
十分な性能
軽量ながらも、要約、チャット、コード生成、情報抽出など、多様なタスクで高いパフォーマンスを発揮します。
想定される主な用途
その特性から、Gemini Flashは以下のような分野での活躍が期待されています。
- 応答速度が重要なチャットボットやAIアシスタント
- リアルタイムでの文章要約や翻訳
- 大量データに対する高速なラベリングや分類
- アプリケーションへのAI機能の組み込み(低遅延が求められる場合)
Gemini ProやUltraと比較すると、複雑な推論や長文の生成能力では譲る部分があるものの、速度とコストが重要な場面では非常に強力な選択肢となります。
Gemini 2.5 Flashは画像生成に対応しているのか?

さて、本題の「画像生成」機能についてです。Gemini 2.5ファミリー全体として、高度な画像生成能力を備えています。テキストによる指示(プロンプト)から、非常に高品質で多様な画像を生成することが可能です。
では、Gemini Flashモデル自体が直接、画像生成機能を持っているのでしょうか?
現時点でのGoogleの発表や技術資料に基づくと、Gemini 2.5シリーズの画像生成機能は、主に高性能モデル(ProやUltraなど)や、Googleの画像生成に特化したAIモデル「Imagen」シリーズと連携して提供されることが多いです。
Gemini Flashは、その軽量・高速という特性上、複雑な画像生成プロセスを単体で実行するのではなく、ユーザーからの指示(プロンプト)を受け取り、それを解釈して画像生成エンジン(Imagenなど)に効率的に連携する役割を担う、あるいは生成された画像のメタデータ処理や簡単な編集といった周辺タスクを高速に処理する、といった形で画像生成に関与する可能性があります。
つまり、「Gemini Flashを使って画像生成を指示する」ことは可能ですが、実際に画像を”描画”するコアエンジンは、より高性能なモデルや専用モデルが担っていると考えるのが現時点では妥当です。
Gemini(または関連サービス)による画像生成の特徴
GoogleのAIによる画像生成は、以下のような特徴を持っています。
高品質・高解像度
写実的な写真から、アーティスティックなイラストまで、非常に精細でクオリティの高い画像を生成します。
プロンプトへの忠実度
入力されたテキスト指示の内容を正確に理解し、細かなニュアンスまで反映した画像を生成する能力に長けています。
多様なスタイル
写真、油絵、水彩画、アニメ、3Dレンダリングなど、様々なスタイルに対応可能です。
安全性への配慮
有害または不適切なコンテンツの生成を防ぐための安全対策が組み込まれています。
Geminiにおける「Deep Research」と画像生成の連携
最近、AIの文脈で「Deep Research」という言葉が聞かれることがあります。これは具体的に何を指し、画像生成とどう関係するのでしょうか。
「Deep Research」とは何か?
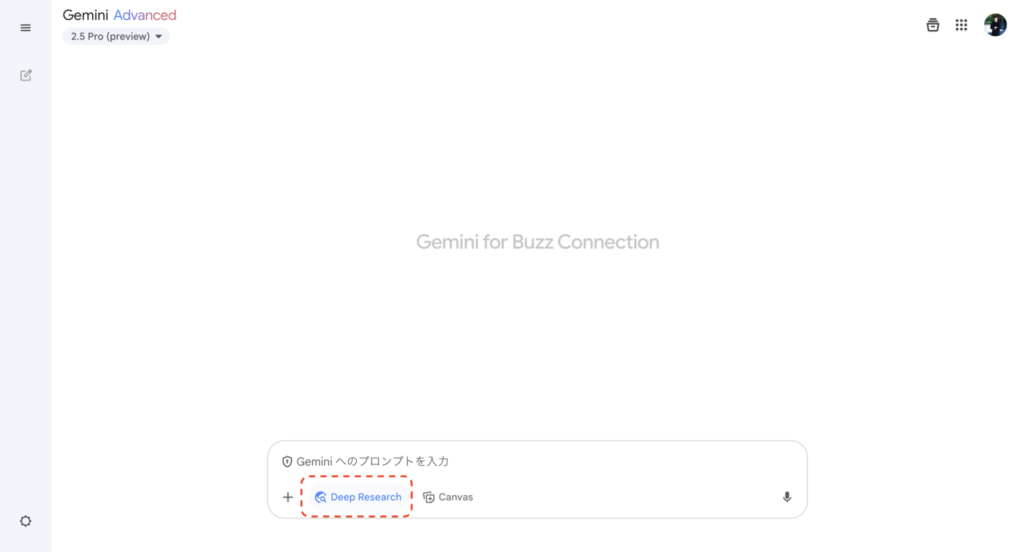
ここでいう「Deep Research」とは、特定の技術名や製品名を指すというよりは、Geminiが持つ高度な情報収集・分析・理解能力そのものを指していると考えられます。Geminiは、単にキーワードに一致する情報をWebから見つけるだけでなく、膨大な情報を読み解き、文脈や背景、ニュアンスまで深く理解する能力を持っています。
広範な情報アクセス
Web上の情報、学術論文、書籍、コードなど、多様なソースから情報を収集・統合します。
深い文脈理解
表面的なキーワードだけでなく、テキスト全体の意味や論理構造、著者の意図などを理解します。
マルチモーダル理解
テキストだけでなく、画像や音声の内容も理解し、それらを関連付けて解釈します。
この「深くリサーチし、理解する能力」が、Geminiの大きな強みの一つです。
Deep Researchが画像生成にもたらす可能性
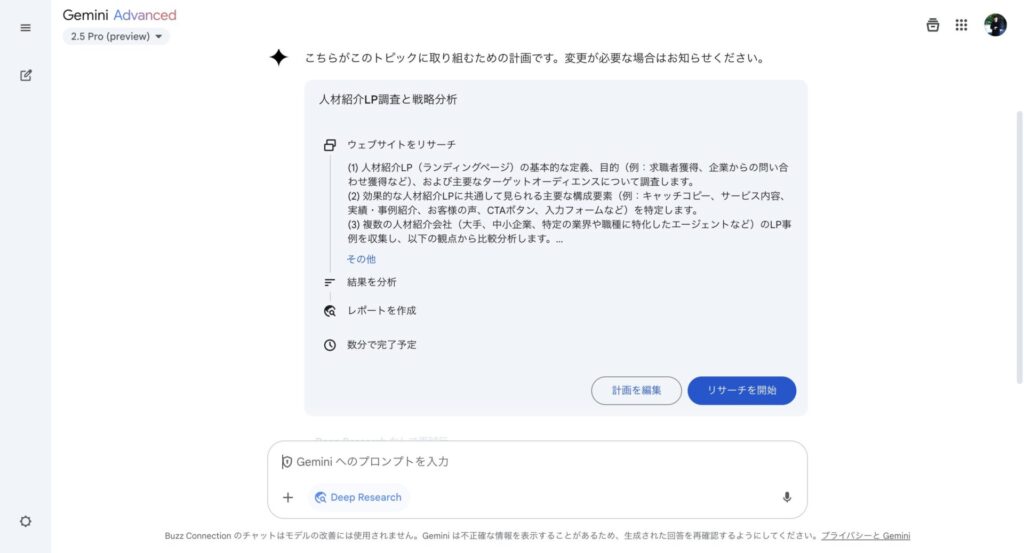
このDeep Research能力は、画像生成においても大きな可能性を秘めています。
複雑・抽象的な指示の実現
「〇〇のような雰囲気で」「△△の哲学を反映した」といった、曖昧で解釈が難しいプロンプトでも、Geminiが背景知識を深くリサーチし、意図を汲み取って画像化することが期待されます。
専門知識の反映
特定の分野(歴史、科学、芸術など)に関する深い知識を基に、時代考証や様式が正確な画像を生成できます。
情報の視覚化
論文やレポートの内容を理解し、その要点やデータを分かりやすく表現するインフォグラフィックやイラストを自動生成するといった応用が考えられます。
プロンプトの補完・拡張
ユーザーの簡単な指示に対して、Geminiが関連情報をリサーチし、より詳細で魅力的な画像になるようプロンプトを内部的に補完・拡張する可能性があります。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
Deep Researchを活用した画像生成の事例(コンセプト例)
現時点で確立された事例というより、今後期待されるコンセプトとしての例を挙げます。
- 事例1|歴史的再現
- プロンプト: 「17世紀オランダ黄金時代の画家フェルメールのアトリエの様子を、当時の資料を詳細に調査して再現した写実的な画像」
- 期待される動作: Geminiがフェルメールや当時のアトリエに関する文献、絵画資料などをリサーチし、光の具合、家具、小物などを可能な限り正確に反映した画像を生成する。
- 事例2|科学的インフォグラフィック
- プロンプト: 「最新のゲノム編集技術CRISPR-Cas9の仕組みについて、専門的な解説記事を複数参照し、中学生にも理解できるように図解したインフォグラフィック」
- 期待される動作: Geminiが関連する科学記事や論文を読み解き、その複雑なプロセスを正確かつ分かりやすく視覚化する。
- 事例3|コンセプトアート
- プロンプト: 「『失われた古代文明アトランティス』をテーマにした壮大なファンタジー映画のコンセプトアート。様々な伝説や研究を踏まえ、独自の解釈で水中都市を描いて。」
- 期待される動作: Geminiがアトランティスに関する多様な情報をリサーチ・統合し、オリジナリティあふれる想像力豊かな画像を生成する。
このように、Geminiの「Deep Research」能力は、単にテキストを画像に変換するだけでなく、知識や理解に基づいた、より高度で知的な画像生成を実現する可能性を秘めているのです。
実践!Gemini (Flash連携) での画像生成の使い方
Geminiの画像生成機能は、主に以下のプラットフォームを通じて利用できます(提供状況は変更される可能性があります)。
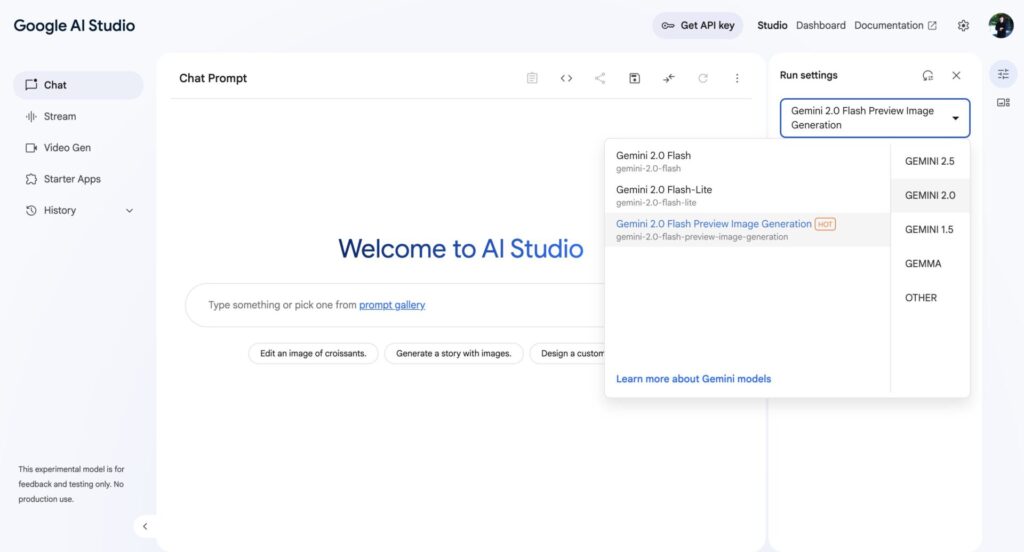
利用可能なプラットフォーム
開発者向けのWebベースのツール。プロトタイピングやAPIキーの取得が可能です。
Vertex AI (Google Cloud)
Google Cloudの統合AIプラットフォーム。より高度なカスタマイズや本番環境へのデプロイに適しています。
Gemini アプリ (スマートフォン)
モバイルアプリ版のGeminiでも、一部の環境で試験的に提供されている可能性があります。(提供状況は地域やバージョンにより異なります)
各種Googleサービスへの統合
Google Workspace (Docs, Slidesなど) やその他のサービスに、画像生成機能が組み込まれる動きも進んでいます。
利用したい環境や目的に合わせて、適切なプラットフォームを選択しましょう。
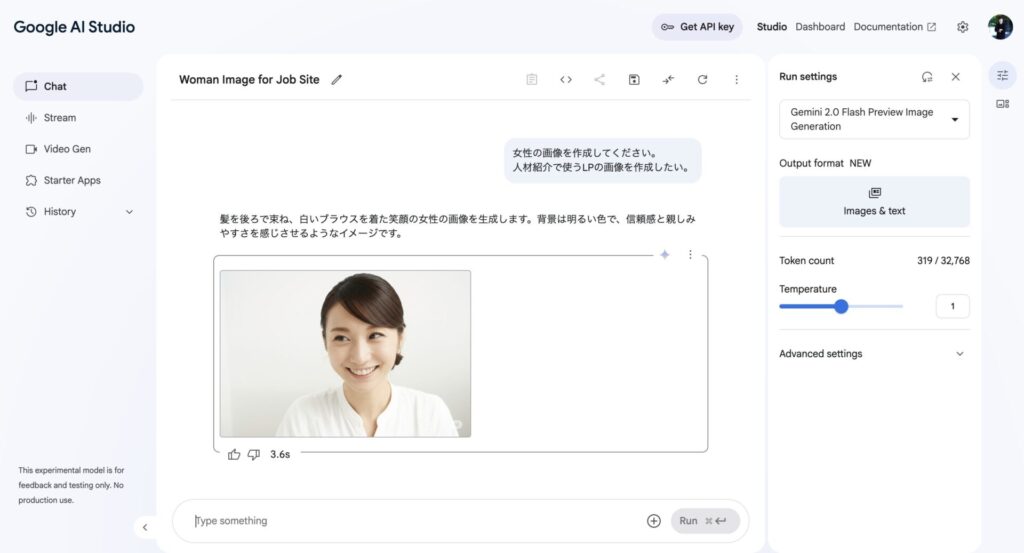
基本的な画像生成の手順
どのプラットフォームでも、基本的な手順は共通しています。
- 画像生成機能を選択 プラットフォーム内で、画像生成(Image Generation)の機能やメニューを選びます。
- プロンプトを入力 生成したい画像の内容をテキストで具体的に指示します。
- (任意)パラメータ設定 生成する画像の枚数、アスペクト比(縦横比)、スタイル、ネガティブプロンプト(生成してほしくない要素)などを設定できる場合があります。
- 生成実行 「生成 (Generate)」ボタンなどをクリックします。
- 結果確認・調整 生成された画像を確認し、必要であればプロンプトやパラメータを調整して再生成します。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
効果的なプロンプトの書き方のコツ
より良い画像を生成するためには、プロンプトの工夫が重要です。
具体的に記述する
何を(被写体)、どこで(場所・背景)、いつ(時間帯・天気)、どのように(構図・スタイル)描いてほしいかを明確に記述します。
詳細を追加する
色、質感、光の当たり方、感情、雰囲気など、ディテールを加えることで、よりイメージに近い画像が得られます。
スタイルを指定する
「写真風 (photorealistic)」「油絵 (oil painting)」「アニメスタイル (anime style)」「サイバーパンク (cyberpunk)」など、希望する画風を指定します。
試行錯誤する
最初から完璧なプロンプトを書くのは難しいものです。短いプロンプトから始めて、徐々に要素を追加・変更しながら試行錯誤しましょう。
画像生成プロンプト例
- シンプルな例
- A golden retriever walking on a sandy beach at sunset, photorealistic style.
- (夕暮れ時の砂浜を歩くゴールデンレトリバー、写実的なスタイル)
- 少し複雑な例
- Neon-lit street in a futuristic cyberpunk city after rain, wet reflective pavement, cinematic lighting, anime style.
- (未来的なサイバーパンク都市のネオン街、雨上がりで濡れた反射する歩道、映画的な照明、アニメスタイル)
- Deep Research活用を意識した例
- Generate an image visually representing the core concepts of quantum entanglement, using abstract shapes and vibrant colors, inspired by Wassily Kandinsky’s art style, based on recent scientific explanations.
- (近年の科学的説明に基づき、ワシリー・カンディンスキーの画風にインスパイアされた抽象的な形と鮮やかな色を使って、量子もつれの核心概念を視覚的に表現した画像)
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
性能と他のAIとの比較
Gemini(及びImagen)による画像生成の性能は比較的高く評価されています。
品質
生成される画像の解像度やディテールの細かさは、業界トップレベルです。
一貫性
同じプロンプトから生成される画像の品質が安定しています。
プロンプト忠実度
指示内容を正確に反映する能力が高いです。特に、複雑な構図や複数の要素を含む指示にも比較的よく対応します。
他の主要な画像生成AIとの比較
市場には、Midjourney, Stable Diffusion (SDXL), DALL-E 3など、他にも優れた画像生成AIが存在します。それぞれに特徴があります。
Midjourney
アーティスティックで高品質な画像生成に定評がありますが、Discord経由での利用が基本となります。
Stable Diffusion
オープンソースであり、カスタマイズ性が非常に高いのが特徴です。モデルやパラメータの調整次第で多様な画風を生成できますが、使いこなすにはある程度の知識が必要です。
DALL-E 3
ChatGPTとの連携がスムーズで、自然言語での指示に対する理解度が高いとされています。
Gemini(Google)の強みは、Google検索などで培われた高度な言語理解能力(これがDeep Researchにも繋がる)、Imagenモデルの高い描画性能、そしてGoogleの広範なエコシステム(クラウド、アプリ、サービス)との連携にあると言えるでしょう。特にGemini Flashと連携することで、高速な応答と効率的な処理を実現しながら、高品質な画像生成を利用できる可能性があります。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
利用料金と今後の展望
Gemini Flashや関連する画像生成機能の利用料金は、利用するプラットフォームやAPIの使用量によって異なります。
Google AI Studio
一定の無料枠が提供されることが多いですが、制限を超える利用には料金が発生します。
Vertex AI
使用した計算リソースやAPIコール数に応じた従量課金制が基本です。
Gemini アプリなど
アプリ内での利用については、無料またはサブスクリプションモデルとなる可能性があります。
最新の料金体系については、各プラットフォームの公式サイトで確認が必要です。
GoogleはAI開発に継続的に注力しており、Geminiファミリーも今後さらに進化していくことが予想されます。画像生成機能についても、品質向上、新機能追加、対応スタイルの増加などが期待されます。
同時に、AIによる画像生成には、著作権、プライバシー、フェイク画像の生成といった倫理的な課題も伴います。Googleは「責任あるAI (Responsible AI)」の原則に基づき、安全対策やガイドラインの整備にも取り組んでいます。利用者側も、これらの点を理解し、倫理的に配慮した利用を心がけることが重要です。
まとめ
この記事では、Googleの最新AIモデル「Gemini 2.5 Flash」と、注目される「画像生成」機能、そして「Deep Research」との関係性について解説しました。
Gemini Flashは、高速・効率的な処理を得意とする軽量モデルです。
Gemini (Google AI) は高品質な画像生成能力を持ち、Flashモデルはこのプロセスに効率的に連携する可能性があります。
Deep Research(Geminiの高度な情報処理能力)は、より文脈に沿った、知識に基づいたインテリジェントな画像生成を実現する鍵となります。
Gemini Flashと画像生成技術の組み合わせは、クリエイティブなアイデアを素早く形にしたり、複雑な情報を分かりやすく視覚化したりと、様々な分野で革新をもたらす可能性を秘めています。
AIによる画像生成は、もはや専門家だけのものではありません。ぜひ、Google AI StudioやGeminiアプリなどを通じて、あなた自身のアイデアをGeminiで画像にしてみてください。試行錯誤しながら、AIとの新たな対話と創造の可能性を探ってみてはいかがでしょうか。
Gemini 2.5 Flash 公式サイト
https://deepmind.google/technologies/gemini/flash
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
【1分で完了】AI活用度診断
あなたのAI活用度を5つの観点で診断し、レーダーチャートで可視化。得意分野と伸ばすべきAIスキルが一目でわかります。
診断は無料で1分程度で完了するので、自分のAIスキルを伸ばしたい方はぜひ診断してみてください。
バズコネのおすすめ投稿












-
 Gemini最新アップデート|Google Gemini 2.5 Pro徹底解説
Gemini最新アップデート|Google Gemini 2.5 Pro徹底解説
-
Gemini(ジェミニ)と Google Workspace 連携で業務爆速!設定方法からGmail・カレンダー・ドキュメント・ドライブ活用術まで徹底解説


この記事の監修者
関連記事
-
Google AI Studioの料金ガイド|コスト試算と設定手順を解説
-
Geminiを活用した画像編集の完全ガイド|手順と最短で仕上げるコツ
-
Google AI Studioを活用した画像生成の手順とプロンプトのコツ
-
Nano Banana Pro(ナノバナナプロ)とは?|使い方・料金から漫画・資料作成・広告バナー作成のためのプロンプト全集
-
Geminiの活用事例12選|業務に活かせる使い方とプロンプト例
-
Gemini 3とは?Web制作・スライド作成の実例や料金を徹底解説
-
Gemini Gemsとは?使い方・活用方法やGPTsとの違いを解説
-
Gemini(ジェミニ) AI自動化 |「スケジュールされたアクション」について解説









コメント