
GPT-image-1とは?──OpenAI最新画像生成モデルをビジネス目線で徹底解説
近年、目覚ましい進化を遂げる画像生成AI。その最前線を走るOpenAIが、待望の最新モデル「GPT-image-1」を発表しました。
本記事では、このGPT-image-1が持つ革新的な機能、ビジネスにおける強み、料金体系、ライセンス、安全性、
そして具体的な活用事例まで、詳細なAPI情報やコード例も交えながら徹底的に解説します。
最新のAIトレンドを掴み、ビジネスを加速させるヒントがここにあります。
この記事はこんな人におすすめ
- 生成AIの最新動向を押さえ、ビジネスチャンスを探りたいマーケターや企画担当者
- DALL·EやMidjourneyといった既存ツールからのステップアップを検討しているクリエイター
- 社内提案や導入検討のために“仕組み・料金・安全性”を網羅的に理解したいビジネスパーソン
- 実際にAPIを利用して画像生成・編集機能を自社サービスに組み込みたい開発者
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!

GPT-image-1の概要
まずは、GPT-image-1がどのようなモデルなのか、その内容に迫りましょう。
「言葉から画像」を超えるネイティブ・マルチモーダル
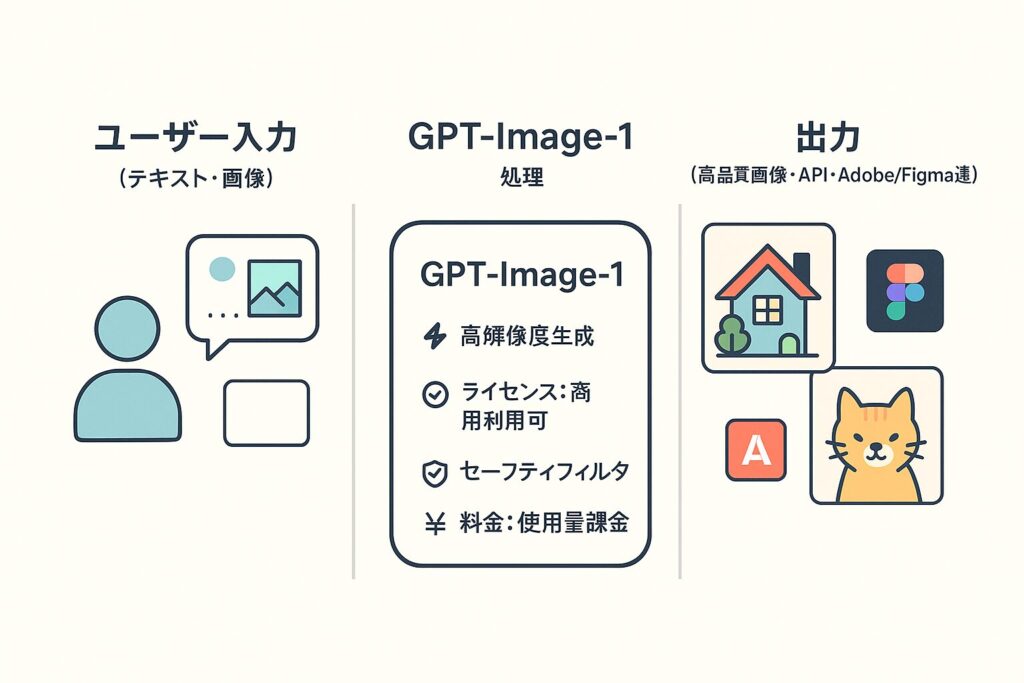
GPT-image-1は、多くのユーザーを魅了したChatGPT(特にGPT-4oなど)の高度な画像生成機能を、開発者がより柔軟に利用できるようAPI(Application Programming Interface)として提供するものです。
単なる機能の一部ではなく、独立した最先端の画像生成モデルとして位置づけられています。
「言葉から画像」を超えるネイティブ・マルチモーダル
GPT-image-1の最大の特徴は「ネイティブ・マルチモーダル」である点です。
これは、単にテキスト(言葉)を入力して画像を生成するだけでなく、テキストと画像の両方を同時に入力として受け付け、それらの情報を統合的に理解して最終的な画像を生成できることを意味します。
従来の代表的な画像生成モデルであるDALL·E 3と比較すると、その進化は明らかです。
GPT-image-1は、DALL·E 3に対して主に以下の2点で大きなアドバンテージを持っています(TechCrunch報道より)。
テキスト描画精度の劇的な向上
生成画像内に文字を含める場合、従来モデルでは文字化けや不自然な配置が課題でした。GPT-image-1ではこの点が大幅に改善され、ロゴデザインやポスター制作など、テキスト要素が重要なシーンでの活用が現実的になりました。
画像から画像への編集がワンリクエストで可能
既存の画像を入力し、「この画像の背景を夜景に変えて」「人物の服装をジャケットにして」といった指示(テキストプロンプト)を与えるだけで、高精度な画像編集が可能です。従来は複数のステップやツールが必要だった作業が、APIへの一度のリクエストで完結します。
これにより、単にゼロから画像を生成するだけでなく、既存のアセットを基にしたバリエーション作成や修正作業の効率が飛躍的に向上します。
搭載先はChatGPTだけじゃない
GPT-image-1のインパクトは、OpenAIのサービス内に留まりません。発表と同時に公開された「Images API」を通じて、サードパーティのツールへの組み込みが急速に進んでいます。
The Vergeなどの報道によると、Adobeの「Firefly」や「Express」、デザインコラボレーションツールの「Figma」、オンラインデザインプラットフォームの「Canva」といった主要なクリエイティブ・デザインツールが、GPT-image-1の採用を表明、または既に実装を開始しています。
例えばFigmaでは、デザインカンプ上で直接テキストプロンプトを入力するだけで、複数のデザインラフ案を瞬時に生成し、そのままFigma上で編集を続けるといった、シームレスなワークフローが実現可能になります。
これにより、アイデア出しからプロトタイピングまでの速度が劇的に向上することが期待されます。
モデル比較:最適なモデルを選ぶ
Image APIでは、用途に応じて複数の画像生成モデルを選択できます。それぞれの特徴を理解し、目的に合ったモデルを選びましょう。
| モデル名 | 対応APIエンドポイント | 主な特徴・ユースケース |
|---|---|---|
| gpt-image-1 | 生成 (Generations)<br>編集 (Edits)<br>(Responses API サポート予定あり) | 推奨モデル。ネイティブ・マルチモーダル。指示の忠実性、テキスト描画、詳細な編集能力、現実世界の知識活用に優れる。高品質。 |
| dall-e-3 | 生成 (Generations) のみ | DALL·E 2よりも高画質。より大きな解像度をサポート。プロンプトへの忠実性も高い。 |
| dall-e-2 | 生成 (Generations)<br>編集 (Edits)<br>バリエーション (Variations) | 低コスト。複数画像の同時リクエスト(nパラメータ)に強い。インペインティングやバリエーション生成が可能。 |
基本的には、最新かつ最も高性能な gpt-image-1 の利用が推奨されます。 特に、プロンプトの指示を正確に反映させたい場合や、画像内のテキスト精度、既存画像の高度な編集を行いたい場合に強みを発揮します。
gpt-image-1利用に関する注意点
gpt-image-1モデルを責任ある形で利用するため、OpenAIは開発者コンソールからAPI組織検証 (Organization Verification) の完了を要求する場合があります。 利用を開始する前に、自身の組織の検証ステータスを確認しておきましょう。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
5つの強み
gpt-image-1がビジネスシーンで特に注目される理由を、5つの強みから解説します。
| 強み | 解説 |
|---|---|
| ① テキスト描画精度 | ロゴやポスターなど複雑なレイアウトでも文字化けが激減 |
| ② スタイルの網羅性 | Ghibli風からフォトリアルまで“世界知識”でトーンを調整 |
| ③ 品質レベルを選択可能 | low / medium / high の3段階でコストと画質を最適化 |
| ④ 高速生成 | medium品質なら平均3〜4秒、UIで即時プレビューが可能 |
| ⑤ セーフティ & 透かし | 生成画像すべてにC2PAメタデータが自動埋め込みされ、出所証明とブランドリスク低減に寄与 TechCrunch |
強み解説① テキスト描画精度
ロゴやキャッチコピーを含む広告バナー、図解中のラベルなど、画像内のテキスト精度が大幅に向上しました。TechCrunchも指摘するように、これによりデザイン業務でのAI活用範囲が大きく広がります。
強み解説② スタイルの網羅性
「ジブリ風」「サイバーパンク調」「水彩画タッチ」など、多様なスタイル指示に対応。膨大な学習データに基づく「世界知識」により、ブランドイメージやコンセプトに合わせた微妙なニュアンスも再現可能です。
強み解説③ 品質レベルを選択可能
生成画像の品質を low / medium / high から選択できます。ラフ案なら low、最終成果物なら high など、用途とコストに応じて最適化できます。
強み解説④ 高速生成
medium 品質なら平均3〜4秒程度で生成可能(OpenAI発表目安)。インタラクティブなUIでのプレビュー表示など、スピードが求められる場面にも対応します。(ただし、複雑なプロンプトでは遅延が生じる可能性あり。後述の「制限事項」参照)
強み解説⑤ セーフティ & 透かし
生成画像には自動でC2PA準拠の電子透かしとメタデータが付与され、AI生成であることの証明と出所追跡が可能です(TechCrunch報道)。加えて、後述するコンテンツモデレーション機能により、不適切なコンテンツの生成リスクも低減されます。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
料金体系—トークンベースで詳細解説
gpt-image-1の利用料金は、APIリクエストで消費される「トークン」数に基づいた従量課金制です。
基本的な料金と1枚あたりの概算コスト
OpenAI公表の1,024×1,024ピクセル生成例に基づく概算コストは以下の通りです。
| 品質 | 入力トークン単価 (/100万tok) | 出力トークン単価 (/100万tok) | 1枚あたり概算コスト* |
|---|---|---|---|
| Low | $5 | $10 | 約$0.02 (約3円) |
| Medium | $5 | $10 | 約$0.07 (約11円) |
| High | $5 | $10 | 約$0.19 (約30円) |
Google スプレッドシートにエクスポート
* 1ドル=155円で換算。実際の単価はプロンプトの長さ(入力トークン数)や画像サイズによって変動します。最新の正確な料金はOpenAI公式サイトをご確認ください。
トークン数とコストの関係:サイズと品質の影響
gpt-image-1 は、画像を生成する際にまず特殊な「画像トークン」を生成します。最終的なコストと生成時間(レイテンシー)は、この画像トークンの数に比例します。 画像サイズが大きく、品質設定が高いほど、より多くのトークンが必要になります。
サイズと品質ごとの画像トークン数の目安は以下の通りです。
| 品質 | 正方形 (1024×1024) | 縦長 (1024×1536) | 横長 (1536×1024) |
|---|---|---|---|
| Low | 272 トークン | 408 トークン | 400 トークン |
| Medium | 1056 トークン | 1584 トークン | 1568 トークン |
| High | 4160 トークン | 6240 トークン | 6208 トークン |
これに加えて、プロンプトとして入力したテキストのトークン数もコスト計算に含まれる点に注意が必要です。
詳細なテキストトークンおよび画像トークンあたりの価格については、OpenAIの公式料金ページを参照してください。
OpenAI公表の1,024×1,024px生成例を換算。実際の単価はプロンプト長で変動。TechCrunch
上記のように、最高品質でも1枚あたり数十円程度という、非常にコスト効率の高い料金設定となっています。大量の画像を生成する必要があるマーケティングキャンペーンや、Eコマースの商品画像バリエーション作成などにおいても、費用対効果の高い運用が可能です。
商用ライセンス & 権利帰属
生成した画像の権利関係も、ビジネス利用における重要な確認事項です。OpenAIの利用規約およびコンテンツポリシーを遵守する限りにおいて、GPT-image-1 (Images API経由)で生成された画像の著作権は、原則として生成したユーザーに帰属します(OpenAI Help Center情報)。
これにより、ユーザーは生成した画像を自由に再販したり、商品化(グッズ制作など)したり、広告素材として利用したりすることが可能です。ただし、著名人の肖像や既存の著作物を模倣するような指示は避け、公序良俗に反しない範囲での利用が前提となります。
さらに、前述のC2PA準拠の電子透かしが自動付与される点も、ビジネス上のメリットとなります。これにより、制作した画像素材を提供する際や、クライアントに納品する際に、「この画像はAIによって生成されたものである」という事実を明確に伝えることができます。これは、透明性の確保や、将来的な法的・倫理的なリスクを軽減する上で役立ちます。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
画像生成品質ベンチマーク
Midjourney V7との比較
Tom’s Guideの比較テストでは、gpt-image-1 (ChatGPT 4o経由)がフォトリアル表現、複雑な構図、テキスト入りポスターなど多くの項目でMidjourney V7を上回り、特に指示への忠実性とテキスト再現性で優位性を示しました。一方、Midjourneyは依然として芸術的な表現力において高い評価を得ています。ビジネス用途での「指示通りの生成」には gpt-image-1 が有利と言えそうです。
API実装ガイド(機能別コード例)
gpt-image-1 を使った画像生成・編集の基本的な実装方法をPythonコード例と共に紹介します。
基本的なセットアップ
まず、OpenAIライブラリをインストールし、APIキーを設定してクライアントを初期化します。
Python
# pip install openai
from openai import OpenAI
import base64
import os
# APIキーを設定 (環境変数推奨)
# client = OpenAI(api_key="YOUR_API_KEY")
client = OpenAI() # 環境変数 OPENAI_API_KEY が設定されていればキーは不要
① 画像を生成する (Generations API)
テキストプロンプトから新しい画像を生成します。n パラメータで複数枚同時生成も可能です(デフォルトは1枚)。
Python
prompt = """A children's book drawing of a veterinarian using a stethoscope to listen to the heartbeat of a baby otter."""
try:
result = client.images.generate(
model="gpt-image-1",
prompt=prompt,
n=1, # 生成枚数
size="1024x1024", # サイズ指定
quality="high" # 品質指定
)
# レスポンスからBase64エンコードされた画像データを取得
image_base64 = result.data[0].b64_json
if image_base64:
image_bytes = base64.b64decode(image_base64)
# ファイルに保存
with open("otter_drawing.png", "wb") as f:
f.write(image_bytes)
print("Generated image saved as otter_drawing.png")
else:
# URLが返ってくる場合 (将来的な仕様変更の可能性)
image_url = result.data[0].url
print(f"Image URL: {image_url}")
# 必要に応じてURLから画像をダウンロードする処理を追加
except Exception as e:
print(f"An error occurred: {e}")
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
② 画像を編集する (Edits API)
既存の画像を基に、新しい画像を生成したり、特定部分を変更したりします。
a) 参照画像を使って新しい画像を生成する

複数の画像を参考に、それらの要素を含む新しい画像を生成します。
Python
prompt = """Generate a photorealistic image of a gift basket on a white background labeled 'Relax & Unwind' with a ribbon and handwriting-like font, containing all the items in the reference pictures."""
try:
result = client.images.edit(
model="gpt-image-1",
image=[ # 参照画像をリストで渡す
open("body-lotion.png", "rb"),
open("bath-bomb.png", "rb"),
open("incense-kit.png", "rb"),
open("soap.png", "rb"),
],
prompt=prompt,
n=1,
size="1024x1024"
)
image_base64 = result.data[0].b64_json
if image_base64:
image_bytes = base64.b64decode(image_base64)
with open("gift-basket.png", "wb") as f:
f.write(image_bytes)
print("Edited image saved as gift-basket.png")
except FileNotFoundError:
print("Error: One or more reference image files not found.")
except Exception as e:
print(f"An error occurred: {e}")
b) マスクを使って画像の一部を編集する(インペインティング)

画像の一部(マスクで指定した透明部分)を、プロンプトに基づいて描き変えます。黒い部分は維持されます。
Python
# マスク要件:
# - 編集元画像 (image) とマスク画像 (mask) は同じ形式、同じサイズである必要があります。
# - ファイルサイズはそれぞれ 25MB 未満。
# - マスク画像はアルファチャンネルを持っている必要があります (透明部分を指定するため)。
prompt = "A sunlit indoor lounge area with a pool containing a flamingo"
try:
result = client.images.edit(
model="gpt-image-1",
image=open("sunlit_lounge.png", "rb"), # 編集元画像
mask=open("mask.png", "rb"), # マスク画像 (透明部分が編集対象)
prompt=prompt,
n=1,
size="1024x1024" # 画像とマスクのサイズ
)
image_base64 = result.data[0].b64_json
if image_base64:
image_bytes = base64.b64decode(image_base64)
with open("composition.png", "wb") as f:
f.write(image_bytes)
print("Inpainted image saved as composition.png")
except FileNotFoundError:
print("Error: Image or mask file not found.")
except Exception as e:
print(f"An error occurred: {e}")
- Tips: 白黒画像からアルファチャンネル付きマスクを作成するには、画像編集ソフト(GIMP, Photoshopなど)で黒い部分を選択し、選択範囲を反転して透明にする、といった操作でアルファチャンネルを追加・保存します。
出力オプションのカスタマイズ
APIリクエスト時にパラメータを指定することで、出力画像を細かく制御できます。
size: 画像サイズ。"1024x1024"(正方形),"1024x1536"(縦長),"1536x1024"(横長) など。quality: 品質レベル。"low","medium","high"から選択。デフォルトは"auto"(medium相当)。標準品質 (medium以下) の正方形が最も高速です。response_format: 出力形式。"b64_json"(Base64エンコードされたJSON、デフォルト) または"url"(一時的な画像URL)。output_format: (※ 将来的なパラメータの可能性、またはドキュメント上の補足情報) 生成画像のファイル形式。png(デフォルト),jpeg,webpをリクエスト可能。output_compression: (※jpeg/webp形式指定時) 圧縮レベルを0〜100で指定。例:output_compression=50で50%圧縮。background: 背景の透明度。"transparent"を指定すると背景が透明になります(pngまたはwebp形式、medium/high品質推奨)。デフォルトは不透明。
例:透明な背景の画像を生成する
Python
prompt = "Draw a 2D pixel art style sprite sheet of a tabby gray cat"
try:
result = client.images.generate(
model="gpt-image-1",
prompt=prompt,
size="1024x1024",
quality="high",
response_format="b64_json",
# output_format="png", # 形式を指定する場合 (API仕様確認要)
background="transparent" # 背景を透明に
)
image_base64 = result.data[0].b64_json
if image_base64:
image_bytes = base64.b64decode(image_base64)
with open("cat_sprite_transparent.png", "wb") as f:
f.write(image_bytes)
print("Transparent background image saved as cat_sprite_transparent.png")
except Exception as e:
print(f"An error occurred: {e}")
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
API連携の全体像
システムに組み込む際は、以下のような流れを想定すると良いでしょう。 (※ ここに、フロントエンド → バックエンドサーバー → OpenAI API → (C2PA付与) → 画像データ/URL返却 → バックエンドサーバー → CDN/S3へ保存 → フロントエンドへURL/画像通知、といったシーケンス図を挿入すると理解が深まります。)
API実装ガイド(最短3ステップ)
自社のサービスや業務フローにGPT-image-1を組み込みたい開発者向けに、基本的なAPI利用の流れを解説します。
1. APIキーの取得と環境設定: まず、OpenAI Platformでアカウントを作成し、APIキーを取得します。取得したAPIキーは環境変数などに設定しておきます(例: OPENAI_API_KEY)。
2. APIエンドポイントへのリクエスト送信: curlコマンドなどを用いて、OpenAIのImages APIエンドポイントにPOSTリクエストを送信します。以下は、基本的な画像生成(generations)のリクエスト例です。
Bash
curl https://api.openai.com/v1/images/generations \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-image-1",
"prompt": "夕暮れのサイバーパンク都市、ネオン輝く高層ビルとホバーカー",
"quality": "high",
"size": "1024x1024",
"n": 1
}'
- エンドポイント: 新規生成は
/v1/images/generations、画像編集は/v1/images/edits、画像のバリエーション作成は/v1/images/variationsを使用します。 - 主要パラメータ:
model:gpt-image-1を指定。prompt: 生成したい画像の内容をテキストで記述します。quality:low,medium,highから選択し、コストと品質を調整します。size: 生成する画像のサイズを指定します(例:1024x1024,1792x1024など)。アスペクト比の指定も可能です。n: 一度に生成する画像の枚数を指定します。
3. レスポンスの処理と画像保存: APIからのレスポンスはJSON形式で返却され、生成された画像のURL(一時的なもの)が含まれています。アプリケーション側でこのURLから画像をダウンロードし、自社のCDN(Content Delivery Network)やAmazon S3などのストレージサービスに保存して利用します。
図解イメージ:フロントエンド→Backend→OpenAI API→CDN配信のシーケンス図を挿入(API Call latency/C2PA付与ポイント記載)。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
連携事例で学ぶ導入メリット
GPT-image-1(Images API)は、既に様々な企業で導入され、具体的な成果を上げています。
Adobe (Firefly / Express)
デザインツール内で直接、高品質な画像素材を生成・編集できるようにすることで、バナー広告やSNSサムネイルなどの作成ワークフローを大幅に効率化しています。
Figma
デザインプラットフォーム上で、テキスト指示からプロトタイプ用の画像を即座に生成・反映させる機能を提供。アイデアの視覚化とデザインプロセスの高速化を実現しています。
Instacart
オンライン食料品配達サービスにおいて、レシピ提案機能で使用する料理画像をGPT-image-1で自動生成。魅力的な画像を掲載することで、ユーザーのクリック率向上に貢献しています。
Gamma
AI搭載のプレゼンテーション作成ツールにおいて、スライドの内容に合わせたイラストや図解、装飾イメージの生成にGPT-image-1を活用。年間5億枚以上の画像を生成し、ユーザーの資料作成時間を大幅に短縮しています。(OpenAI発表)
これらの事例は、GPT-image-1が単なる画像生成ツールに留まらず、既存のワークフローを革新し、具体的なビジネス成果(効率化、エンゲージメント向上、コスト削減など)に貢献するポテンシャルを持つことを示しています。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
マーケティング & 業務ユースケース8選
GPT-image-1は、様々なビジネスシーンで活用できます。
ここでは、具体的な8つのユースケースをご紹介します。
| カテゴリ | 具体像 |
|---|---|
| 広告クリエイティブ | A/Bテスト用バナーを大量生成しCPCを最適化 |
| Eコマース | カラバリ写真をAI合成し撮影コストを削減 |
| SNS運用 | トレンドに合わせた“映える”投稿を即日作成 |
| ブログ/メディア | アイキャッチや図解をノーコードで量産 |
| 資料作成 | プレゼン用イラストやモックアップを即挿入 |
| 生成AI研修 | “プロンプト×画像”のハンズオン教材を作成 |
| ブランドガイド | 定義済みカラーパレット・フォントで統一出力 |
| オンデマンド印刷 | グッズ用デザインを個別カスタマイズ生成 |
これらのユースケースはほんの一例です。自社の課題や目的に合わせて、GPT-image-1の活用可能性を探ってみてください。
セーフティ設計とブランドリスク低減策
ビジネスでAIを利用する上で、安全性と信頼性の確保は不可欠です。OpenAIは、GPT-image-1(Images API)において、以下のようなセーフティ機能とリスク低減策を提供しています。ビジネス利用における信頼性と注意点を解説します。
セーフティ機能
OpenAIは安全な利用を促進するため、以下の機能を提供しています。
- コンテンツモデレーション: 全てのプロンプトと生成画像は、OpenAIのコンテンツポリシーに基づきフィルタリングされます。
gpt-image-1では、APIリクエスト時にmoderationパラメータで感度を調整できます。auto(デフォルト): 標準的なフィルタリング。年齢不適切なコンテンツ等を制限。low: より制限の少ないフィルタリング。
- Watermark (C2PA): 生成画像に自動でC2PA準拠の電子透かし・メタデータを付与し、AI生成の証明とトレーサビリティを提供します。
ブランドリスク低減策
- IPチェック推奨: 商用利用前に、生成画像が既存の著作物と類似していないか確認しましょう。
- プロンプトログ監査: APIリクエストのログを管理し、利用状況の透明性を確保します。
GPT-image-1の制限事項
高性能な gpt-image-1 ですが、以下の点に留意が必要です。
- 遅延 (Latency): 特に複雑なプロンプトや高解像度/高品質設定の場合、画像の生成・編集に最大で2分程度の時間がかかることがあります。リアルタイム性が重要なアプリケーションでは注意が必要です。
- テキストレンダリング: DALL·Eシリーズより大幅に改善されましたが、特定のフォントの正確な再現や、複雑なレイアウトにおけるテキストの配置・明瞭さには、まだ課題が残る場合があります。
- 一貫性 (Consistency): キャラクターやブランドロゴなど、特定の要素を複数の画像で一貫して表現させ続けることは、まだ難しい場合があります。複数回生成すると微妙に異なる結果になることがあります。
- 構成制御 (Composition Control): プロンプトへの追従性は高いものの、非常に厳密な要素の配置(例:「AをBの真上に配置」)や、複雑な空間構造の正確な再現は、苦手な場合があります。
これらの制限を理解した上で、適切なプロンプト設計や利用シーンの選定を行うことが重要です。
“AIで勝てる人”へ。実務で活かす力を身につけよう
オンラインAIスクール「BuzzAcademy」なら専属講師が基礎から実務まで伴走し、実務で活かせるAIスキルを最短習得。
案件紹介サポートも実施しており、副業初心者でもスキルを身につけながら着実に実績を積み上げられます。
今なら無料相談で、あなたに最適なAIキャリア・学習プランをご提案中!
まとめ
GPT-image-1は、単に「綺麗な絵を描くAI」という段階から、ユーザーの意図(プロンプト)を正確に理解し、ビジネス上の要求に応える高品質な画像を、安全かつ効率的に生成できるツールへと進化しました。
特に、テキスト描画精度の向上、ネイティブ・マルチモーダルによる画像編集能力、C2PAによるトレーサビリティ確保は、マーケターやビジネスユーザーが具体的な「成果指標」(KPI)に直結させやすい機能と言えるでしょう。
AdobeやFigmaといったクリエイティブツールとの連携、InstacartやGammaのようなサービスでの導入事例は、その実用性とビジネスインパクトを如実に示しています。
まずは、OpenAI Platformで提供されている無償クレジットなどを活用し、自社の業務に関連するプロンプトでGPT-image-1の画像生成を試してみてはいかがでしょうか。既存のDALL·EやMidjourneyで生成した画像と比較したスクリーンショットなどを社内で共有し、具体的な活用方法について議論を始めることが、次の一手へと繋がるはずです。
GPT-image-1は、クリエイティブ制作の民主化を加速させ、ビジネスにおける視覚コミュニケーションのあり方を大きく変える可能性を秘めています。この機会にぜひ、その力を体験してみてください。



この記事の監修者
関連記事
-
 Chat GPTで効率的な動画台本作成!ニュース記事を基に解説
Chat GPTで効率的な動画台本作成!ニュース記事を基に解説 -
ChatGPTとClaudeを徹底比較!機能やパフォーマンスの違い・ユーザーの声を調査
-
【ChatGPT 活用事例】生成AIを利用した同時通訳の可能性
-
誰でも業務効率アップ!ChatGPTのエクセル活用術
-
【ChatGPT】カスタムGPTs完全ガイド|作成方法や活用事例から販売方法まで徹底解説
-
ChatGPTの法人契約ではTeamとEnterpriseどちらを選ぶ?各プランの比較と判断基準
-
難しい小論文が一瞬で!? ChatGPTを活用した論文執筆方法を解説
-
ChatGPTでPDFファイルを読み込む方法を徹底解説|分析作業を効率化








コメント